In case you didn't know, there's a fantastic Data Engineering community on Discord (invite here). I've been a member of this server since the very start, and I've seen it grow substantially over the years. If you read that last sentence again, you'll notice that it's really vague. When was the start? Was I really there at the start, or did I just join (waves hands) a while ago? How much has the server grown over time? How many members are there? How often does the average user post? What are the most popular channels? I could go on.
When I was thinking about all of this one day I realized I was uniquely placed to answer these questions for a few reasons:
- I'm a data engineer by trade who spends all day working with databases and moving data around, and who also writes and reads a lot of code for fun.
- I've been tinkering with Discord bots for several years, having written several bots for an online game that I used to play, as well as a fun meme-generating bot. Additionally, I recently wrote the Plumber bot for the Data Engineering Discord server to manage static content such as rules, FAQs, and recommended resources.
- I'm an admin on the server and so have the requisite access to do a project like this.
So with that, I set out to find a way to learn more about this community, and play around some new(ish) tech along the way.
Getting the Data
The full source for the bot is at available on my Github account, but I'll walk through some of it below.
First I identified what I wanted to collect. I knew I wanted to gather information on the members of the server, but I also wanted information on messages. In order to get messages, I'd need channels. Luckily these three entities are naturally related and form a compact and simple data model. I defined the three tables as follows:
CREATE TABLE IF NOT EXISTS users( id INT64 PRIMARY KEY, name VARCHAR, joined_at TIMESTAMP, created_at TIMESTAMP ); CREATE TABLE IF NOT EXISTS channels( id INT64 PRIMARY KEY, category VARCHAR, category_id INT64, created_at TIMESTAMP, mention VARCHAR, name VARCHAR, topic VARCHAR ); CREATE TABLE IF NOT EXISTS messages( id INT64 PRIMARY KEY, channel_id INT64, user_id INT64, content VARCHAR, clean_content VARCHAR, jump_url VARCHAR, created_at TIMESTAMP );
Once that was all done, here was the structure of the tables:
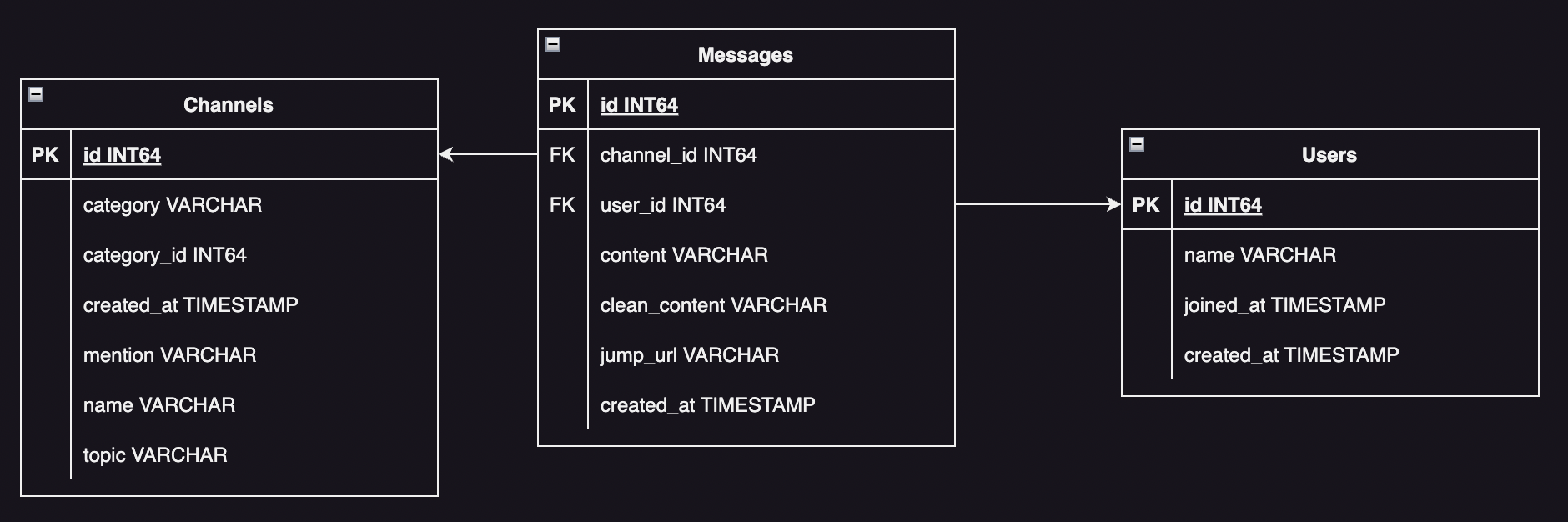
Now that I had the tables defined I had to collect the data. I used boilerplate code I had written for the Plumber bot to create the connection to Discord, and used the DuckDB Python API to create and manage my database.
NOTE
I used DuckDB for a few reasons. First, it's a somewhat new piece of technology that I had read a lot about but hadn't had a good use case for yet. Second, it was supposed to have a similar API to SQLite which I had used in the past and was familiar with. And third, I knew that I'd be issuing analytical queries on my laptop against a potentially large dataset, and DuckDB was designed for exactly that use case. It was a natural fit.
The heart of the program comes down the on_ready() method, which runs once the bot has connected to the server.
async def on_ready(self) -> None: # Connected to the Discord server server = client.get_guild(self.server_id) print(f"Backfill: {self.backfill}") # Create a connection to a file called 'server.db' con = duckdb.connect("server.db") # CREATE IF NOT EXISTS self.create_table_users(con) self.create_table_channels(con) self.create_table_messages(con) # Get all users await self.get_users(con, server) # Get all channels, and for each channel get all messages await self.get_channels_and_messages(con, server, self.backfill) # Close connection to DuckDB and Discord con.close() await client.close()
At a high level this code connects to the Discord API, finds a given server by its ID, creates or connects to a DuckDB database, creates the required database tables, and then pulls and stores all users, channels, and messages from the provided server. You can run it with the --backfill flag to re-collect all data from the beginning (overwriting any existing content due to INSERT OR REPLACE), and then you can run it again without the --backfill flag to just update the existing data.
Due to the way the Discord API works, users and channels are very quick to retrieve, but getting messages can take a bit longer. I also acknowledge that I'm doing row level inserts here which is a sub-optimal method for loading data into a columnar system. Doing a bulk load via a COPY command would likely be more performant. Still, I'm able to collect and store all of the data from the Data Engineering server in ~20 minutes so no need to over-engineer.
Analysis
Even with only three tables there are a lot of questions we can answer. Let's list some out, starting with the basics, and then write some queries to solve them:
How many members are there?
select count(*) from users;
| count_star() |
|---|
| 7874 |
How many users have joined each month?
select
datetrunc('month', joined_at) as month,
count(*) as join_count
from users
group by 1
order by 1;
| month | join_count |
|---|---|
| 2019-04-01 | 99 |
| 2019-05-01 | 93 |
| 2019-06-01 | 62 |
| 2019-07-01 | 67 |
| 2019-08-01 | 74 |
| 2019-09-01 | 72 |
| 2019-10-01 | 68 |
| 2019-11-01 | 86 |
| 2019-12-01 | 56 |
| 2020-01-01 | 94 |
| 2020-02-01 | 125 |
| 2020-03-01 | 155 |
| 2020-04-01 | 112 |
| 2020-05-01 | 131 |
| 2020-06-01 | 142 |
| 2020-07-01 | 128 |
| 2020-08-01 | 112 |
| 2020-09-01 | 133 |
| 2020-10-01 | 161 |
| 2020-11-01 | 147 |
| 2020-12-01 | 136 |
| 2021-01-01 | 185 |
| 2021-02-01 | 244 |
| 2021-03-01 | 330 |
| 2021-04-01 | 254 |
| 2021-05-01 | 212 |
| 2021-06-01 | 200 |
| 2021-07-01 | 108 |
| 2021-08-01 | 129 |
| 2021-09-01 | 139 |
| 2021-10-01 | 171 |
| 2021-11-01 | 107 |
| 2021-12-01 | 140 |
| 2022-01-01 | 183 |
| 2022-02-01 | 191 |
| 2022-03-01 | 163 |
| 2022-04-01 | 185 |
| 2022-05-01 | 268 |
| 2022-06-01 | 157 |
| 2022-07-01 | 241 |
| 2022-08-01 | 193 |
| 2022-09-01 | 188 |
| 2022-10-01 | 225 |
| 2022-11-01 | 187 |
| 2022-12-01 | 156 |
| 2023-01-01 | 192 |
| 2023-02-01 | 200 |
| 2023-03-01 | 149 |
| 2023-04-01 | 187 |
| 2023-05-01 | 160 |
| 2023-06-01 | 177 |
Plotted:

Looks like we had a peak around mid-2020 which coincides with a bump in messages around that time (see below), and users joining continues at a relatively steady pace.
How many posts are there in total?
select count(*) from messages;
| count_star() |
|---|
| 125582 |
Which channels get the most activity?
-- Omits channels with no messages as messages is the base table
select
c.name as channel_name,
count(*) as message_count,
round(count(*)/(select count(*) from messages)*100,2) as pct_total
from messages m
left join channels c
on m.channel_id = c.id
group by 1
order by 2 desc;
| channel_name | message_count | pct_total |
|---|---|---|
| general | 30124 | 23.99 |
| help | 20958 | 16.69 |
| career | 17658 | 14.06 |
| noob | 13627 | 10.85 |
| off-topic | 8878 | 7.07 |
| interviewing | 7187 | 5.72 |
| databases | 4912 | 3.91 |
| architecture | 3343 | 2.66 |
| batch | 3257 | 2.59 |
| cloud | 2846 | 2.27 |
| resources | 2681 | 2.13 |
| book-club | 1928 | 1.54 |
| data-science | 1624 | 1.29 |
| server-talk | 985 | 0.78 |
| memes | 934 | 0.74 |
| streaming | 924 | 0.74 |
| faang | 754 | 0.6 |
| job-board | 739 | 0.59 |
| bi-tools | 712 | 0.57 |
| looking-for-work | 239 | 0.19 |
| self-promotion | 227 | 0.18 |
| staff-chat | 206 | 0.16 |
| 2020-10-22-show | 200 | 0.16 |
| topic-of-the-week | 178 | 0.14 |
| 2022-02-01-advent-of-code-2022 | 174 | 0.14 |
| moderation-log | 98 | 0.08 |
| staff-bot-spam | 96 | 0.08 |
| bot-development | 41 | 0.03 |
| github-updates | 24 | 0.02 |
| workshops | 10 | 0.01 |
| dev-chat | 9 | 0.01 |
| roles | 3 | 0.0 |
| curated-resources | 2 | 0.0 |
| pr-messages | 2 | 0.0 |
| honeypot | 1 | 0.0 |
| faq | 1 | 0.0 |
Maybe we have too many channels 🤔
What time of day is the server the most active?
select
datepart('hour', created_at) as hour_of_day,
count(*) as message_count,
round(count(*)/(select count(*) from messages)*100,2) as pct_total
from messages
group by 1
order by 1;
| hour_of_day | message_count | pct_total |
|---|---|---|
| 0 | 4996 | 3.98 |
| 1 | 4875 | 3.88 |
| 2 | 5140 | 4.09 |
| 3 | 3849 | 3.06 |
| 4 | 3896 | 3.1 |
| 5 | 2857 | 2.28 |
| 6 | 2135 | 1.7 |
| 7 | 2465 | 1.96 |
| 8 | 2754 | 2.19 |
| 9 | 3020 | 2.4 |
| 10 | 2999 | 2.39 |
| 11 | 3175 | 2.53 |
| 12 | 4494 | 3.58 |
| 13 | 5359 | 4.27 |
| 14 | 6959 | 5.54 |
| 15 | 9049 | 7.21 |
| 16 | 9043 | 7.2 |
| 17 | 9978 | 7.95 |
| 18 | 8348 | 6.65 |
| 19 | 6703 | 5.34 |
| 20 | 5933 | 4.72 |
| 21 | 5767 | 4.59 |
| 22 | 5859 | 4.67 |
| 23 | 5929 | 4.72 |
Here it is plotted:

So it looks like activity tends to peak around 17:00 UTC, which would be towards the end of the workday in Europe and afternoon in the US.
How has activity on the server changed over time?
select
datetrunc('month', created_at) as month,
count(*) as message_count
from messages
group by 1
order by 1;
| month | message_count |
|---|---|
| 2019-04-01 | 1145 |
| 2019-05-01 | 1641 |
| 2019-06-01 | 1226 |
| 2019-07-01 | 789 |
| 2019-08-01 | 547 |
| 2019-09-01 | 688 |
| 2019-10-01 | 973 |
| 2019-11-01 | 870 |
| 2019-12-01 | 755 |
| 2020-01-01 | 1290 |
| 2020-02-01 | 1289 |
| 2020-03-01 | 2074 |
| 2020-04-01 | 1947 |
| 2020-05-01 | 2588 |
| 2020-06-01 | 2274 |
| 2020-07-01 | 2605 |
| 2020-08-01 | 2067 |
| 2020-09-01 | 2132 |
| 2020-10-01 | 4029 |
| 2020-11-01 | 4200 |
| 2020-12-01 | 5073 |
| 2021-01-01 | 4517 |
| 2021-02-01 | 4339 |
| 2021-03-01 | 3867 |
| 2021-04-01 | 3458 |
| 2021-05-01 | 2985 |
| 2021-06-01 | 3464 |
| 2021-07-01 | 3152 |
| 2021-08-01 | 3053 |
| 2021-09-01 | 1490 |
| 2021-10-01 | 2735 |
| 2021-11-01 | 2555 |
| 2021-12-01 | 2395 |
| 2022-01-01 | 2239 |
| 2022-02-01 | 1501 |
| 2022-03-01 | 1422 |
| 2022-04-01 | 2588 |
| 2022-05-01 | 5838 |
| 2022-06-01 | 3873 |
| 2022-07-01 | 3682 |
| 2022-08-01 | 2972 |
| 2022-09-01 | 3099 |
| 2022-10-01 | 2349 |
| 2022-11-01 | 2761 |
| 2022-12-01 | 1816 |
| 2023-01-01 | 2406 |
| 2023-02-01 | 2141 |
| 2023-03-01 | 3206 |
| 2023-04-01 | 2347 |
| 2023-05-01 | 1477 |
| 2023-06-01 | 1653 |
I also plotted this and added a horizontal line representing the average posts per month over all time:

I'm not entirely sure what to make of this. It seems that we had a peak around the end of 2020, then again mid-2022, and right now (end of June 2023) we're in a bit of a dip.
How many members joined Discord specifically to join this server?
This is assuming that users who joined the server on the same day they joined Discord signed up specifically to join the Data Engineering server
select
count(*) as count,
round(count(*)/(select count(*) from users)*100,3) as pct_same_day
from users
where datediff('day', created_at, joined_at) = 0;
| count | pct_same_day |
|---|---|
| 1461 | 18.555 |
Conclusion
There's a lot more analysis that could be done, but I think with even the little effort I put into this I was able to learn some interesting things about this server and its activity. It was also great to finally have a chance to get hands on with DuckDB. While the dataset was by no means large (the database file shows only 56MB on my filesystem), DuckDB still handled it like a champ and had all the functionality I was looking for. I can definitely see myself using it for other projects in the future.
Awesome
Is there anyway I can get my hands on this dataset?
Awesome!
Cool stuff